【Pythonメモ】 後置 if
後置 if
最近、rubyみたいに後置if無いかなと ぐぐってみました。
以下はメモ
# testはtrueの際の出力 if True なら test = "true" test = "true" if True else "false" print(test) #true # Falseになった際、elseの式 test2 = "false" if False else "false" print(test2) #false # rubyみたいにかけない。 elseはつけないといけない test3 = "true" if True print(test3) #error になる
Slack BOT + Backlog APIでタスク管理する。
仕事の管理ツール
現在、仕事でプロジェクト管理は backlog をコミュニケーションツールは slack を使っています。 会議はあまりないので、仕事の打ち合わせはslack上が多いです!
slackとbacklogを使う際の問題点・・・
最近になってようやく(汗)、slackとbacklogに慣れてきたのですが、 両方使ってきて自分なりの不満点も見えてきました。
- backlogにあがった課題URLのリンクをSLACKにいちいちコピペするのがだるい。
- backlogページにログインしたくない (仕事で用いるページ、アプリは少なくしたい→slack、エディタに集中)
上記の課題点を克服すべく、Slack Botを作成してみました!
SLACK BOT環境
python version 主に使用したモジュール
モジュール slackbotについて
slackbotを作成する場合、RealTimeMessaging APIを 用いる必要があります。(APIはWebSocketベース)
こちらのモジュールを用いると
Websocket周りの通信をうまいことラップしてくれます。
モジュールインストールは pip install slackbot で大丈夫です。
setup(hello world的なヤツ)
最低限の実行に必要な手順は以下
1. SLACBOT API KEYの取得
2. 実行ファイル、環境設定ファイルの指定となります。
※ 1についてはググると色々とあるので、割愛します!
実行ファイル、環境設定ファイルの指定
実行フォルダ直下に
API_TOKEN = <slack_api_key> # デフォルトの返信 default_reply = "hello!" #カスタマイズプログラム読み込み指定 PLUGINS = ['plugins.reply_backlog_task']
from slackbot.bot import Bot
def main():
bot = Bot()
bot.run()
if __name__ == "__main__":
main()
と記述し、run.pyを実行すると、botが起動します。
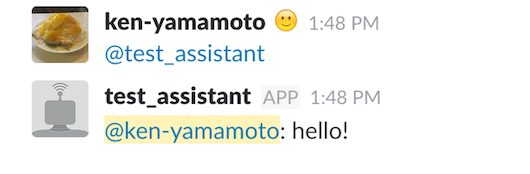
カスタマイズ
次に特定のフレーズに反応した際の処理を作成します。
slackbot_settings.pyに PLUGINSというで指定したファイル(./plugins/reply_backlog_task.py)
に独自の処理を追加することが出来ます。
今回は、以下の処理をプログラムすることにしました。
処理手順
1. pj:プロジェクト名とスラックでメンション(slack)
2. pj:に続くプロジェクト名をキャプチャする。(python)
3. キャプチャした単語をtrelloAPIでを呼び出して未完了タスクを呼び出す。(python)
4. backlog担当PJ未完了タスクを表示(slack)
プログラム
from slackbot.bot import respond_to from slackbot.bot import listen_to import json import re import requests # backlogクエリパラメータ dict返し def issue_data(projectId): issue_data = { 'parentChild':0, 'count':100, #取得上限数 'projectId[]':projectId, 'statusId[]': [1,2],#1→未対応、2→処理中 } return issue_data # backlog api convert pj_name → pj_id def convert_project_num(project_name): dict = { "pj1":11111, "pj2":22222 } return dict[project_name] # backlog api request def backlog_get_issues(projectId): url = HOST + '/api/v2/issues?apiKey=' + <backlog_api_key> r = requests.get(url,issue_data(projectId)) return r.json() # デコレータの引数にマッチするキーワードを指定し、マッチした後続の関数を実行 # デコレータの引数は正規表現も可能 # 正規表現パターンでマッチした、キャプチャは第二引数に引き渡される @respond_to(r'pj:(.+)[\s ]?$') def mention_func(message,project): texts = backlog_get_issues(convert_project_num(project)) for t in texts: text = "【未対応案件リスト】" text += "\n" text += "担当者:" text += str(t['assignee']['name']) text += "\n" text += str(t['description']) message.reply(text) # slackに返信 time.sleep(1)
ごちゃごちゃしてダサいですが、動きました(^^)

これからもカスタマイズしていって、便利なslack仕事アシスタントbotを作っていきたいです!
参考ページ!
【linuxメモ】date
date
dateとは「 日付や時刻を表示,設定する 」ことです。
$ date 2017年 7月29日 土曜日 00時58分03秒 JST # +をつけると表示形式を指定出来る date +%Y%m%d:%H-%M-%S 20170726:20-23-50
日時を明記したファイル作るケースはよくあるのではないでしょうか。
$ touch `date +%Y%m%d_%H:%M:%S`.txt # touch(新規ファイル作成) バッククオート(日時出力を実行その中身を出力) $ ls | grep txt 20170729_00:45:30.txt
【メモ】XMLパース方法
xml
個人的備忘録として、XMLのファイルを元にパースメモを記します。 document
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
XMLファイル読み方
一行目 <?xml version="1.0"?>の箇所は「そのテキストが XML であることを示すための宣言」です。
パースする際には無視して構わない。
二行目 <data>は一番の要素であり、XML構造データの始まりを示している。
ルートディレクトリと呼ばれる。
三行目 <country>はの入れ子状態となっており、子要素と呼ばれる。
parse方法
from xml.etree import ElementTree
x = 'sample.xml' # 読み込むxmlファイルのパスを変数に記憶させる
tree = ElementTree.parse(x) # xmlファイルを読み込む
# print(tree)
root = tree.getroot() # ルートを取得する
print(tree.findall('country'))
print(root[0][0].tag)
print(root[0][0].text)
# xpath *→直接の子要素 .→現在の要素
//→現在の要素配下のすべてのレベル上のすべての子要素を選択
print(tree.findall("*/rank"))
print(tree.findall(".//*[@name='Singapore']"))
print(tree.findall(".//"))
for child in root:
print(child.tag, child.attrib)
メソッド(使いそうなところだけ)
- ElementTree.parse … xmlを読み込む
- findall … 現在の要素の直接の子要素を取得 この場合、xmlを読み込んだ際はルートディレクトリから始まるので子要素はcountryタグとなる。
- 指定している要素からさらに子要素をみたい時は「*」を用いる。
- インデックス 移動する位置が面倒な場合は[i]が使える。(i:0,1…) 一個つけると、隣接した子要素のi番目の要素を指定
- 指定したnodeに複数のタグがあり、絞りたい場合は「/タグ名」で絞る。
タグの情報取得
- タグ名を表示したい場合は、指定したタグに「tag」をつける。
- 属性名を表示したい場合は、「attrb」をつける
- テキストを表示したいときは 「text」をつける
メモ xmlint
TravisCI入門しました!
はじめに
Travis CIを利用し始めたので、 備忘録も兼ねてブログに書き込んでおきます。
利点
Travis CIを使うことによる利点は、
となります。
実行の流れ
具体的にTravis CIの設定〜実行の流れを書き下すと、以下の通りとなります。
- TravisCI登録し、指定したGithubのレポジトリ連携
- 連携したフォルダにTravisCI用に設定ファイルを作成
- githubにプッシュすると、設定した環境に応じてTravisCIがテスト実行
- テスト結果に応じて処理
1. についてはTravis CIはGUIが非常に素晴らしく、簡単なので割愛します!
TravisCI用設定ファイル作成
連携したレポジトリのルートディレクトリに以下のようなYAMLファイルを作成します。
language: python python: - "3.5" install: - pip install <パッケージ名> script: - python py_test.py after_success: - <slack通知>
python:はテストするプログラミング言語install:はインストールするパッケージを指定します 注)scriptは実際のテストを行なう作業を記述します。今回は指定したファイルを実行します。after_successとはテスト成功した後の処理を指します。今回はslack通知を記述しておきました。
注)今回はpython標準ツールを使っているので、本来はinstallの必要はありません。
testスクリプト
今回はunittestを用いて以下のように書いてみました!
import unittest class PyTest(unittest.TestCase): def test_equal(self): one = 1 self.assertEqual(one,1, "one is 1") def test_not_equal(self): two = 2 self.assertNotEqual(two,3,"2 not equal 3") def test_almost_equal(self): three = 3.1 self.assertAlmostEqual(three,3,0,"3.1 almost equal 3") def test_assert_regex(self): sentence = "test作業はつまらない。じゃなくて、楽しいぞ〜" self.assertRegex(sentence,'test.+楽.{1,}〜$',"test作業:マッチ") if __name__ == "__main__": unittest.main()
プッシュ後
連携したレポジトリをGithubにプッシュすると自動で指定したテスト (今回はpy_test.py)が実行されます。
テスト結果は以下のようにGUIで表示され、非常にわかりやすいです!
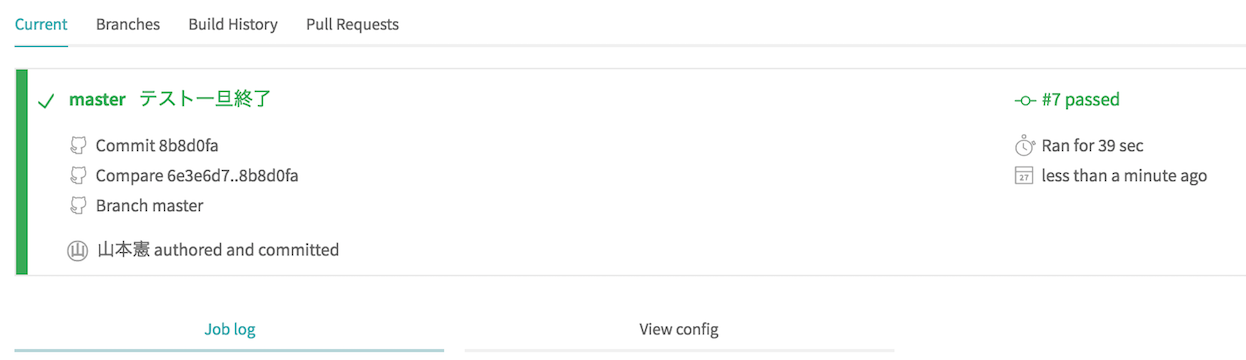
テスト成功後
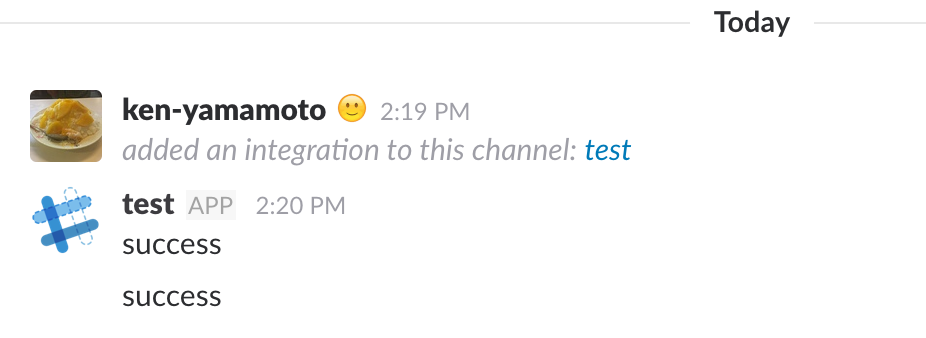
テストが成功したので自動でスラックに投稿されています。(.travis.ymlで記述) チーム開発している時にはテスト結果をいちいち通知を手動で書く必要がなく便利です。
Tensorflow で OLS(最小二乗法) ~その1~
はじめに
先日、Google社製のライブラリTensorflowを使ってみました。 備忘録も兼ねてブログにまとめていきます。
本ブログでは、スクレイピングした賃貸情報データを元に 家賃(非説明変数)と他の情報(説明変数)を用いて回帰分析を行います。
分析対象データ(物件情報)
取得データ変数(抜粋)
| 家賃 | 専有面積 | 管理費 | 礼金 | 最寄り駅から の距離 |
建築年数 | 建築材 |
|---|---|---|---|---|---|---|
| 万円 | m2 | 円 | 万円 | 徒歩N分 | N年 | 木造・鉄筋・鉄骨 |
具体例(抜粋)
スクレイピングデータはこんな感じです。
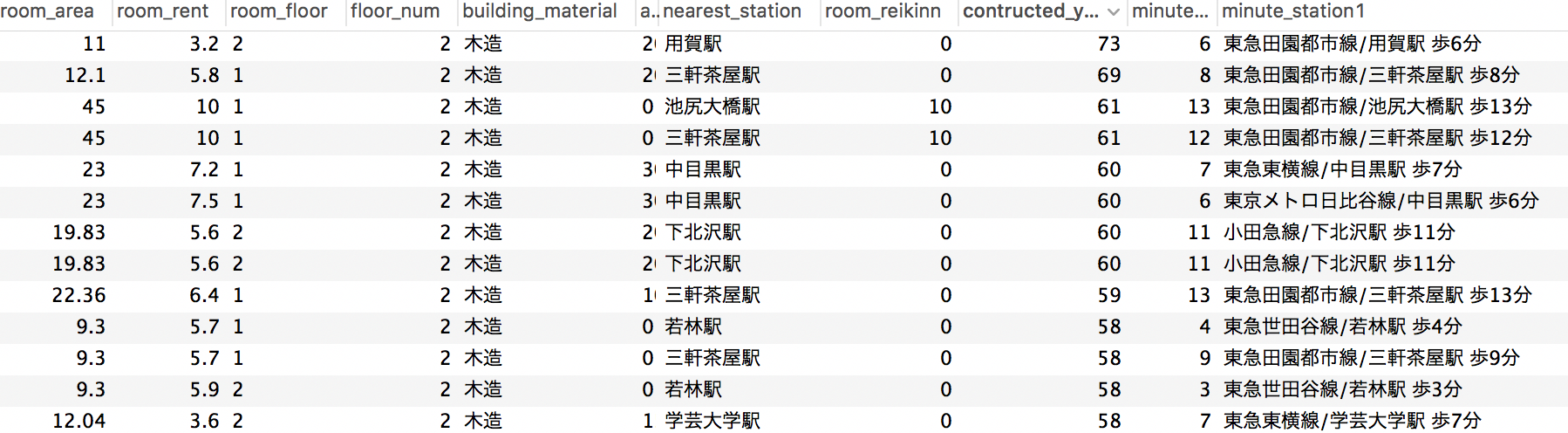
今回分析すること
家賃を非説明変数として、取得したスクレイピングデータを元に 賃料(=家賃+管理費+礼金/24)をどれだけ説明出来るか分析してみます。
今回は前段階としてざっくりと家賃(Y軸)と説明変数候補(X軸)をプロットしてみます。
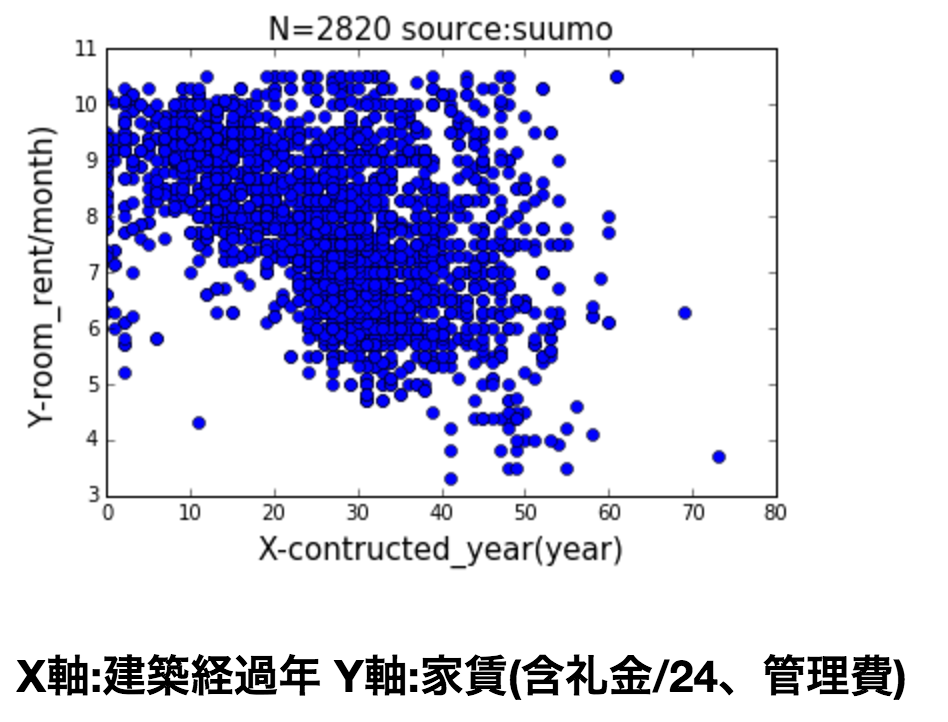
X軸(建築年数)
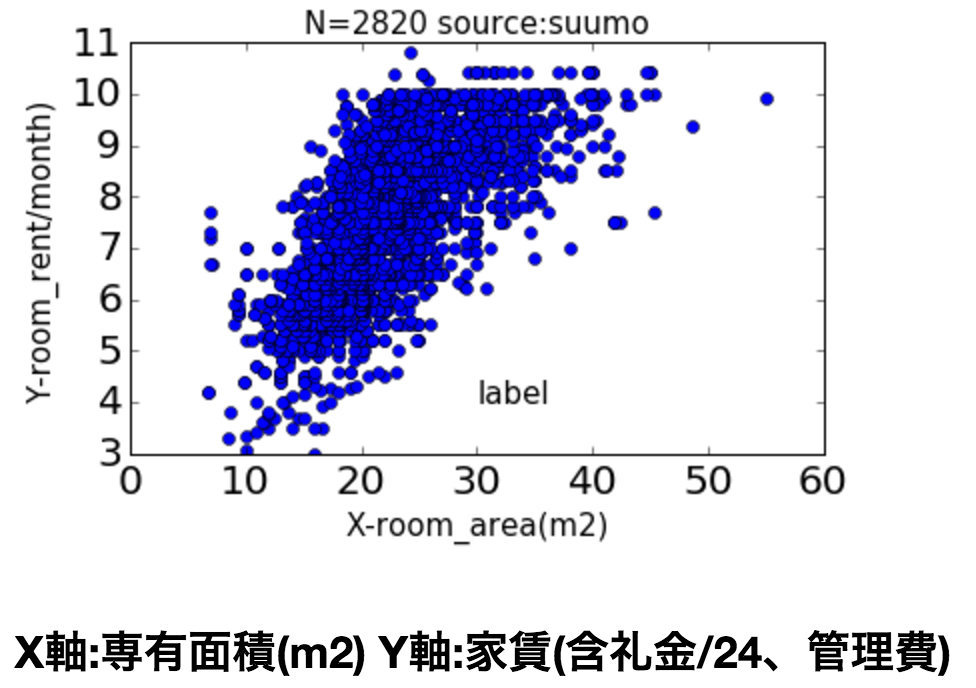
X軸(専有面積m2)
X軸(徒歩分数)
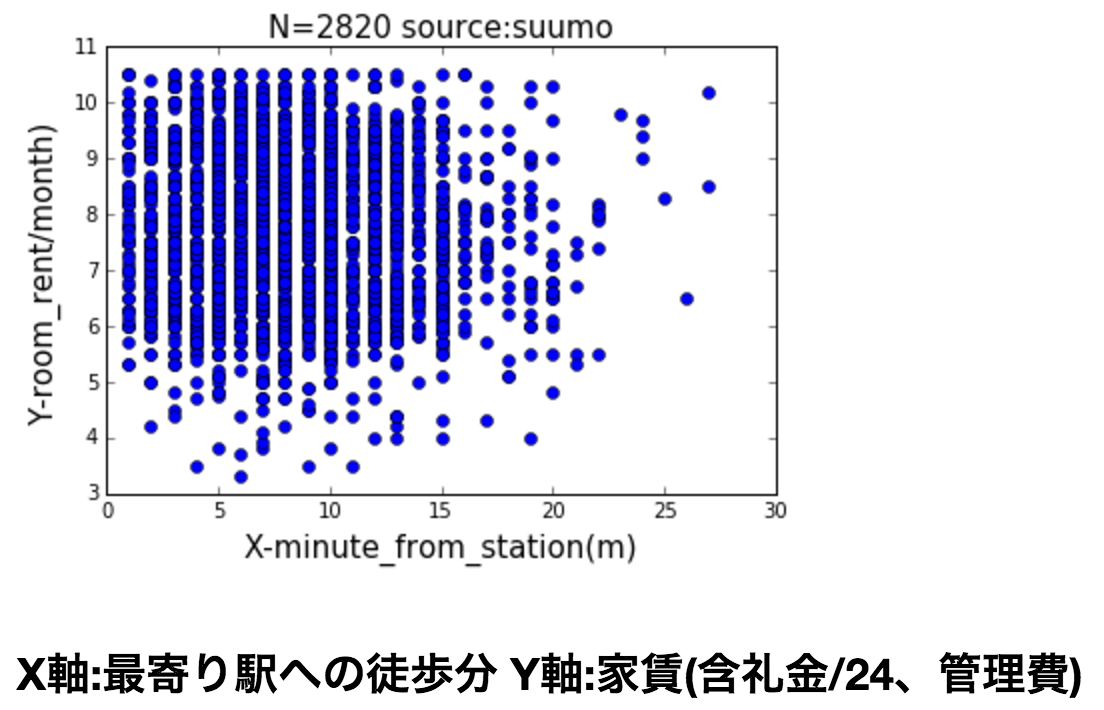
プロットしてみた感じだと、
- 建築年数は賃料と負の相関
- 専有面積は賃料と正の相関
- 最寄り駅からの近さと賃料からは相関は微妙
といった傾向が見えます
次回、賃料に対して上記3つの変数がどの程度影響与えているのか最小二乗法を使ってみます。
【linuxメモ】 cat sed
説明の前提、カレントディレクトリに以下のファイルがあるとする。
hoge1 hoge2 hoge3
cat
- 定義 ファイル内容を標準出力に表示
$ cat hoge.txt hoge1 hoge2 hoge3
と出力される。
-nをつけると、行番号が表示される。
$ cat -n hoge.txt 1 hoge1 2 hoge2 3 hoge2
sed
- 定義 文字列の置換、行の削除を行なう。
- オプション 「i」ファイルを直接編集、「e」スクリプトを実行
置換
eオプションに続いてスクリプト「s/置換前/置換後/」を用いると置換出来る。
# 末尾にgをつけると全て置換、数値の場合はマッチした番号を置換 # 全行で置き換えを実施 テキスト文にある test→hoge $ sed -ie "s/test/hoge/g" hoge.txt # 正規表現も使える。 $ sed -ie "s/./tttt/g" hoge.txt $ sed -ie "s/^hoge$/test/g" hoge.txt
削除
#1行目を削除 $ sed '1d' hoge.txt #1~3行目を削除 $ sed '1,3d' hoge.txt
リダイレクトすれば、勿論新規ファイル作成も出来る。
# hoge → test 置き換えファイル作成 $ sed -e "s/hoge/test/g" > test2.txt